
¿Que es la singularidad?
Es una teoría que predice que llegará un día en un futuro indeterminado (pero no muy lejano) en el que los ordenadores tendrán la capacidad de diseñar otros ordenadores mejor que un ser humano. En principio no parece gran cosa, pero si pensamos que el ordenador en cuestión era diseñado por los propios humanos, entonces los nuevos ordenadores también serán mejores que el ordenador original y los propios humanos, y podrán crear a su vez otros aun mejores. Así podemos entrar en una cadena en la que ordenadores crean otros ordenadores mejores que a su vez crean otros aun mejores, etcétera. Es decir, un punto en que se pierde el control, y tal vez la capacidad de comprender como evolucionan estos ordenadores. La Inteligencia Artificial aumentaría de forma geométrica. Muchas veces se dice que el dia en que el hombre invente este ordenador, sera el último invento de la humanidad.
Este hecho se le llama singularidad por analogía a la singularidad que estudian los físicos. Dentro de estas singularidades, las leyes de la física conocida dejan de ser validas (se supone que existe una singularidad en el interior de los agujeros negros, y también en el origen del Big Bang). De la misma forma, llegado al punto de la Singularidad Tecnológica, es imposible hacer ningún tipo de especulación sobre lo que ocurre después. Es un terreno desconocido. Pero si que podemos especular como se puede llegar a esa situación desde donde estamos. Esta es precisamente la parte más interesante y a la que se están dedicando más esfuerzos de investigación
¿Y este momento está cerca?
Pues depende de quien opine, claro. Algunos defienden que esta cerca, dado el ritmo en que esta evolucionando la informática e Internet, otros lo ven lejano y otros opinan que no ocurrirá nunca. Yo me voy a centrar en los que opinan que está cerca. Aún así, no es algo nuevo, el primero en hacer referencia a la singularidad fue Irving J. Good en 1965 en el artículo "Speculations Concerning the First Ultraintelligent Machine." Advances in Computers, Vol. 6.

Otra figura importante es Raymond Kurzweil, experto en Inteligencia Artificial. Kurzweil desarrolla la idea de base y utilizando la Ley de Moore (enunciada en 1965 por Gordon E. Moore, buen año por lo que parece) que predice un crecimiento exponencial en potencia de calculo y capacidad de los ordenadores, desarrolla su visión en la que predice que en este siglo XXI se fusionarán hombre y máquina (entre otras cosas).
Kurzweil es famoso porque sus predicciones tecnológicas se han cumplido mayoritariamente. Sus ideas están ampliamente desarrolladas en su libro La Singularidad está cerca (2005).
Acontinuacion les mostraré unos videos de la singularidad tecnologica
Parte 1
Parte 2
Parte 3

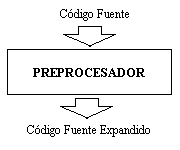
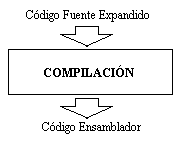
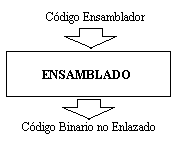
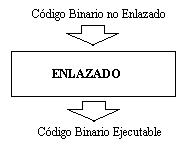

{kind=link}
{kind=link}